
Development
On rebuilding mervyn.online
Sep 25, 2024
Sure I'll throw a blog up on my server. How long could that take, ten minutes?
Oh, Mervyn-of-a-week-ago, you naïve fool. You know you can't ever do things the straightforward way. WordPress who?
(Side note, literally as I began writing this post I got a notification from the WordPress Slack that WP Engine has filed a C&D with Automattic CEO photomatt over him berating WPE during a WordCamp event that they sponsored, and: lmao)

#It's one composer package, what could it cost, 100MB?
To be honest, I'd been sort of half-heartedly poking at reworking my site for the better part of the past year. I've been wanting to learn Laravel for a while and this would be a good way to dip my toe in before working on any bigger projects with it. So I popped up a new branch and opened up a few docs pages and started composer require-ing all over the place off and on for the next few months.
Well, turns out it's easy to get completely lost in the sauce with Laravel. It's a very open platform, which is great after dealing with WordPress and Drupal professionally for years, and having a history with CodeIgniter. But that means it's very easy to justify "oh I'll just install this package" to myself when I want to do something like, say, set up a basic admin panel.
 The git graph of someone who totally has a vision for the thing they're building, trust me.
The git graph of someone who totally has a vision for the thing they're building, trust me.
Anyway long story short is I spent a while making a mess of my codebase trying to get the ultimate relational database tables set up, when I stepped back and thought, "is this really what I want for my personal site?"
No, not really.
I love a complex webapp with a robust API and interconnected parts all over the place, don't get me wrong, but this is a tiny site that I want to exist as a place to say "hi, I'm Mervyn, and I'm here." A place to link to my other stuff and host a small blog with my thoughts and that's about it. Over the course of 8 years I'd made 130 updates to the repo (many of which were updating social links), and then I didn't touch it at all for over a year. I don't want a complicated app that I have to maintain, I want a flexible underlying codebase with relatively few dependencies that I only need to think about when I want to update some content.

#Oh yeah, .md is neat actually
As bad luck would have it, while I was having a crisis over all the time I sunk into going down the wrong path, Cohost announced their imminent shutdown. And it got me thinking again about wanting to set up a blog And as I thought about the posts I enjoyed reading on Cohost and how much its users had done with basically a simple markdown editor (CSS crimes capabilities aside). I realized I first off didn't need to deal with some sort of fancy rich text editor, I don't need to figure out Gutenberg or recreate anything fancy, and second off I don't need a bunch of complicated relational data management to just... put some text up for people to read. But at the same time writing every post in raw HTML would introduce a little too much friction, so markdown is pretty much the perfect middle ground.
So I did a bit of searching around for ways to implement a markdown-based blog. I went over my main reasoning for landing on this setup in my last post, but the two big driving factors were wanting to make it easy for me to write from anywhere, and not wanting to deal with database backups or risk losing all my content.
So I found Prezet.
I'm actually only looking into this now as I write this post, but Prezet has only been around for a few months, with its first proof of concept being released just this past May. I didn't realize just how baby this project was! That said, it seems pretty robust for being in effectively early alpha stages, so I'm not unhappy with this choice for the time being by any means (if anything, maybe I could open some contributions to fix the few grievances I do have so far).
Anyway, at its core Prezet is a collection of models that take in markdown files stored within the Laravel app, parse their frontmatter (metadata) and content, and create a blog index and views to format and display those files as blog posts. It's not too much different in presentation from the various static site generators out there, it just does the processing on view instead of at build time. It provides some nice base templates to work from and is pretty extendable as far as views and styles go, which is nice and definitely something I'll be poking at over time. It's got support for a selection of default frontmatter properties like title, category/tags, draft status, publish date, etc., and also lets you add your own (I've already added type to differentiate between posts and pages like the about page).
I spent some time writing up my first post and getting a feel for how easy it was (generally, pretty easy! a few quirks aside), and relatively quickly had a workable local copy of the site running. Neat! I bet that means I can get this whole thing online in the next few minutes!
It was, of course, another six days before any of this made it to the internet.
#Adding my little customizations
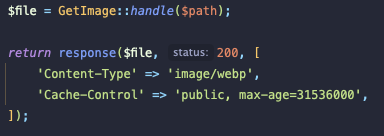
Of course, before I made this all public, I had to make it ever so slightly more presentable. Like I mentioned, there are a couple of little quirks in Prezet that you have to fiddle with if you want to do too much customization. The first is image handling – by default the preprocessor will only accept .png, .jpg, and .webp. And those are hard-coded in the vendor class, so RIP to any .jpegs I export from Lightroom and forget to rename. Even a PNG with transparency doesn't render properly due to the built-in image optimization (a good thing for the sake of bandwidth, but still...). And any sort of animated gif is out of the question. To top it all off, all images get served up with webp headers anyway, so sure. While all of this can theoretically be overridden in sub-classes, it's a bit much for me to want to bother with right now.

The more important thing that I wanted to implement was some custom metadata. Ultimately it'd be fun to add a bunch of extra frontmatter and build in some good old Livejournal or dA-styled "mood, listening to, reading, etc." fields for my posts. Sure I could just dump them in the content but I think metadata is fun. But to start, I at least wanted to let myself denote if a file was an actual blog post, or a more static page, so I could use the latter for things like an about page or contact info or something, and have a way to say "don't show a post date on this or list it on the index."
Adding the extra field was easy, the Prezet docs have some basic info on overriding the Model class and adding your field, and then you just pop it in any given file's frontmatter and you're good to go. The headache came when I needed to actually query and filter by that metadata. While Prezet does create a simple SQLite index database to help with post querying, it only selects a few important bits of metadata to store in columns, like post date and draft status. Most of the metadata goes into a serialized array, which you can't exactly just add to your where clause. So of course instead of trying to work through a clean and efficient solution I just:
$type = $request->input('type', 'post');
if ($type !== 'all') {
$query->where('frontmatter', 'like', '%"type":"' . $type . '"%');
}
...and called it a day. Ah well, it works.
Overall I'm pretty happy with this package, and glad it seems to be seeing active dev work (two new releases since I first installed it last week). But if it doesn't work out, I'm very happy with my decision to keep everything in plain ol' files, so I can move over to whatever else does work at any point.
#Keeping my old landing page
It was already enough work to get the blog set up, so as much as I'd like to rework my landing page at some point, this wasn't the time to do it. The downside to that decision was that page was this weird marriage between a static site and dynamic custom MVC platform that I hacked together along with a colleague back in my side job in undergrad a decade ago. That of course was going to be 0% compatible with Laravel so I still had to make this decision between just turning it into a fully static HTML page, and trying to pick apart and piece together my old template files and libraries and rework them for Laravel. I ended up going with the latter because of two reasons:
- I wanted to keep my silly little functionality where each page load shows a randomized selection of descriptor strings under my name.
- I made the questionable decision some years back to put both my personal and professional domains on the same codebase, and just let the site determine which content to throw up at runtime depending on the request URL. I'm not sure if that's going to be a good idea going forward (less concerned with the separation of identities and moreso with it just being a headache to maintain), but it was easier than separating it out now.
So I got to work porting everything over. Most of this wasn't actually too bad, just lots of replacing my custom template function calls with blade components. I crudely implemented my URL detection in the landing page controller and just kept all the variable content in arrays in the blade templates, so on load it grabs what it needs from either the public or professional array and pops that content on the page. Really not a good way of handling this but I have so little content on the landing page it's... fine it's fine it's okay it's fine.
The biggest headache I encountered was, perhaps predictably, the goddamn JavaScript libraries. Used to be adding fun cool JS functionality to your site was easy; you'd download the latest jQuery.min.js, pop it on your server, and add a script tag before any of your custom scripts. Now everyone wants you to bundle your assets, build an app.js, require your dependencies, do an npm run build... absolute nonsense. But Prezet uses Vite which uses a build pipeline so oh well. It does make writing custom stuff easier. But holy shit is it a pain the moment you need to do anything involving legacy packages. The proper method of adding jQuery and Bootstrap dependencies was an option, but not one I wanted to pursue because this landing page is going to be replaced and I won't be using them moving forward. But trying to just import a vendor JS file or two was flat out not working no matter what I tried. The build pipeline kept pulling them in in an arbitrary order, and refused to acknowledge that I needed jQuery before jQuery UI, and both before Bootstrap, and all three of those before my custom script. Even trying to just link them as static assets instead of bundling was giving me grief, so after an afternoon of headaches I did the sensible thing and just linked to their respective CDNs because I couldn't bring myself to care any longer.
But hey, it all worked out, and I could now visit my local dev homepage to see the old landing page, and hit /blog to see my posts!
#Now to bring it live...
Aaaand then I had to get the whole thing online.
Should be simple, right?
In theory honestly, yes, it should be simple. I already had my EC2 instance running, all my domains pointed at it, SSL all configured... Realistically it could/should be as easy as updating my httpd DocumentRoot and pushing the site files up. But I wanted to be all fancy and make future deployments easy (which I think is reasonable considering making/editing a post would involve a deployment).
In the past, I made use of a git post-receive hook that I wrote for my first internship, again a decade ago, that basically checks the branch that was pushed (checking against the configured prod or dev branch), navigates to the associated webroot, and performs a git pull in place to fetch all changes. This worked fine when there was a 1:1 mapping of what was in the repo to production files, not so much when you have a build process and are running a platform that has to update an index database and clear caches. Doubly so when everything in the webroot is now owned by the vcs:vcs user/group and while that's fine for read-only stuff, things get messy when www-data can't write a log file or update the index. So I needed a better solution.
My first attempt was less than stellar. I figured, "why bother with fancy CI pipelines and having to touch Jenkins again? I'll just add all the build steps to the post-receive hook!" Well first off you still get everything from Apache to Ubuntu complaining about file permissions at you when it's all trying to run as the vcs user, and secondly it turns out that AWS's cheapest tier VMs aren't the best at handling building node packages.
 "Hmm, why is my SSH tunnel not responding or my homepage loading?"
"Hmm, why is my SSH tunnel not responding or my homepage loading?"
So I resigned myself to needing to build the site elsewhere before deploying. I spent the better part of an evening trying to poke at CI deployments through GitHub and AWS CodeDeploy, but between the learning curve that I didn't feel like climbing at the time and the associated extra cost, I gave up fairly quickly. In the end I realized the best path truly is the simplest – just rsync that shit.
I got to work on a simple deploy script to handle everything, so I don't have to run a bunch of different commands every time I want to push something up. And then a quick Lando command that I can pass some config variables to that say where the files are going, so when I'm ready to push up I can just do lando deploy-(dev|prod) and the script will build all of the app packages, check out the correct deployment branch, set a few file permissions, push things up, and be done! Dead simple. Except I still had a couple small issues.
Namely, the blasted file permissions. No matter what I set ahead of time before deployment, there are certain cache files and directories that get their ownership set on deploy to the user doing the deployment. And then when www-data comes along to write a view cache, it gets mad that it doesn't have group write perms. So ultimately I couldn't fully avoid having to SSH into the server manually for a deployment to run another script that would set the proper write access. I did try adding an incron job to have it run when it detected a deployment, but that just crashed the server again, whoops. I'm sure there's more I could look into there that would make for a cleaner solution, but really I'm just glad to have something semi-functional.
#So how does it all work in practice?
Not too bad, actually! I know I'm only two posts in so far but I've got what seems like it might be a decent process:
#1. Write a post
Okay maybe a "draw the rest of the fucking owl" kinda step but I'm not here to talk about my writing process because I sure as hell don't have one. But I did want to make getting some words down easy, so I created a template in my Obsidian vault that pre-populates a new note with the basic frontmatter and generates a post slug, so I don't even have to deal with remembering the default metadata I need to include. I get my thoughts down in that note, do any formatting, and let my vault sync itself across my computers and phone so I can write in bursts from anywhere. Admittedly, sometimes I do also write directly in the site repo, but PhpStorm's markdown editor is decidedly less pretty, and if I want to pick up my writing somewhere else I gotta push and pull the whole site repo.
#2. Get it in the content directory
Whenever I want to see how the post is gonna look on the site, it's as simple as copying it to the content directory (storage/blog/content/YYYY/MM/DD-post-slug is the structure I've settled on for now), spinning up my local dev instance, and loading it up. I've also been creating a branch in the repo to work from for each post, so I can make checkpoints as I write, but I'm thinking those will generally get squashed and rebased onto main whenever I publish.
#3. Push it live
After all my hard work and headaches, this is thankfully fairly easy now. Once I'm good to publish a post, I set the draft property to false, make sure it's on the main branch, and hit lando deploy-prod (if I want to be extra sure it's good I can merge and deploy to dev first, but for content updates this isn't strictly necessary). Everything gets built and updated locally, pushed up to the server, and I can check to see if the permissions broke and SSH in to run my perm script if needed. Overall if I'm honest I'm a fan of this process. It hits a very good balance of "I just gotta get my words written with no friction" and "I like to mess around with technical things and play in the terminal," so I'm happy with it so far. Now just to see how regularly I actually have things to say.
#Final thoughts
I'll admit, I started this last section yesterday, thinking maybe I'd write about some of what I wanted to do next here, like implementing an RSS/Atom feed. But this morning I went ahead and did that so there's now a feed available if you want to keep up with my posts here. It's not 100% perfect – image embedding needs to be set up separately because of the way Prezet handles image optimizations, and it formats section headers a little funny, but like with everything else about this site so far: at least it's there, I can fix it later. Probably.
And part of me still wonders if I should try and figure out how to get a basic comment system implemented here. I don't want to deal with managing a full content database, and I really really don't want to add something invasive like Disqus, but I think there are a few similar options out there that are a bit more privacy-focused I might look into. We'll see.
If nothing else, this has been a fun week-long journey! Still no idea how often I'll post stuff up here but I'd like to give it an honest try. It was a real fun learning experience getting everything working, and there's plenty to do to make it look and function a bit nicer.
That's all for now!
Leave a comment